相信有看過周星馳大話西遊的朋友都對對至尊寶與紫霞仙子之間那幕:"當時那把劍離我的喉嚨只有0.01公分",那種「一眼萬年」或「極致瞬間」的定格是有印象的。在電影中,那是一個情感爆發的瞬間;而在數學的世界裡,這種對「極短瞬間」的捕捉,正是微積分中 「微分」(Differentiation)的核心精神。
捕捉變化的瞬間:微積分與機器學習的最佳解尋找
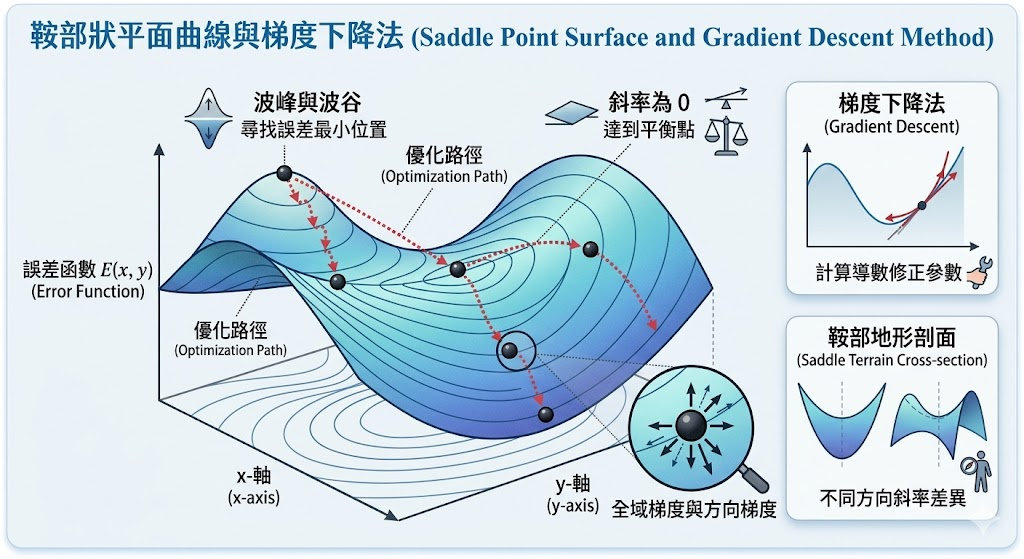
當我們說機器學習在「找答案」,它其實更像是在一片起伏不定的地形中,努力找到最低點。這件事看起來很像數學題,但本質上更像是理解變化、追蹤方向、修正步伐的過程,而這正是微積分最擅長處理的事情。
無論是線性回歸、神經網路,還是更複雜的深度學習模型,背後都離不開同一個核心問題:模型該往哪個方向調整,才能讓誤差變小?微積分提供的導數、偏導數、梯度與鏈式法則,就是回答這個問題的關鍵工具。
1. 為什麼機器學習離不開微積分?
機器學習不是直接把正確答案寫進程式裡,而是讓模型透過資料慢慢逼近答案。這個逼近過程需要一個衡量標準,也就是損失函數。損失函數越小,代表模型預測得越準。
但只知道「現在誤差有多大」還不夠,我們更需要知道「如果把參數調大一點或調小一點,誤差會怎麼變」。這就是導數的角色。導數描述變化率,告訴我們眼前的曲線正在上升還是下降、下降得快還是慢。
- 導數幫助我們判斷單一變數的變化方向。
- 偏導數處理多個參數同時存在的模型。
- 梯度把所有偏導數整理成一個方向向量,指出誤差上升最快的方向。
而訓練模型時,我們通常不朝梯度方向前進,而是往相反方向走,因為那才是讓誤差下降最快的方向。
2. 從損失函數到梯度下降
如果把損失函數想像成一座山,模型訓練就是從山坡某處往低谷前進。梯度下降法的精神非常直覺:每一步都沿著最陡的下降方向前進一小段。
這個更新規則通常可以寫成:
新參數 = 舊參數 - 學習率 × 梯度
這裡的學習率決定了每次跨出的步伐大小。步伐太大,可能直接跨過低點;步伐太小,則會讓訓練速度變得很慢。也因此,理解「方向」和「步幅」兩件事,比死背公式更重要。
- 損失函數回答模型現在表現得好不好。
- 梯度回答模型接下來應該往哪裡調整。
- 學習率回答模型每次該調整多少。
3. 最佳解真的只有一個嗎?
在課本裡,我們常看到漂亮的曲線與唯一的最低點;但在真實的機器學習任務中,地形往往更複雜。模型可能遇到局部最佳解、平台區、鞍點,甚至在不同方向上表現出完全不同的曲率。
這也是為什麼訓練模型不只是「算數學」,還包含許多實作上的判斷。像是初始化方式、資料尺度、批次大小、正規化技巧,都會影響模型是否能順利找到更好的解。
- 局部最佳解代表你已經走到附近最低,但不一定是全域最低。
- 鞍點表示某些方向像谷底,某些方向卻像山脊,容易讓訓練停滯。
- 平坦區域會讓梯度很小,參數更新變慢。
因此,最佳解並不只是算出來的,它也是在演算法設計與訓練策略中逐步逼近的。
4. 鏈式法則如何支撐神經網路學習?
神經網路之所以能訓練,關鍵在於反向傳播,而反向傳播背後最重要的數學基礎,就是鏈式法則。因為神經網路的輸出是層層函數組合的結果,所以當我們要知道某個權重對最終誤差有多少影響時,就必須把每一層的變化串接起來。
鏈式法則讓我們能夠把「最終輸出誤差」一路拆回每一個參數,進而有效率地更新數以萬計甚至數百萬計的權重。這也是為什麼許多人在學深度學習時,一旦真正理解鏈式法則,就會突然看懂整個訓練流程。
可以說,微積分不是神經網路外加的背景知識,而是模型能學習的核心語言。
5. 從數學理解走向實際應用
學微積分不是為了讓每一位學習者都成為數學家,而是為了建立一種可解釋的學習能力。當你知道導數在看變化、梯度在看方向、鏈式法則在拆解影響,就不會只把機器學習當成黑箱工具。
這樣的理解會直接反映在實作上:你比較知道何時該調整學習率、何時該觀察損失曲線、何時模型可能卡在不理想的位置,也更能理解不同優化器為何有不同表現。
機器學習的進步,往往不是一次跳到終點,而是在每一次微小更新中捕捉變化、修正方向,最後慢慢逼近更好的答案。這正是微積分與機器學習最迷人的交會點。
